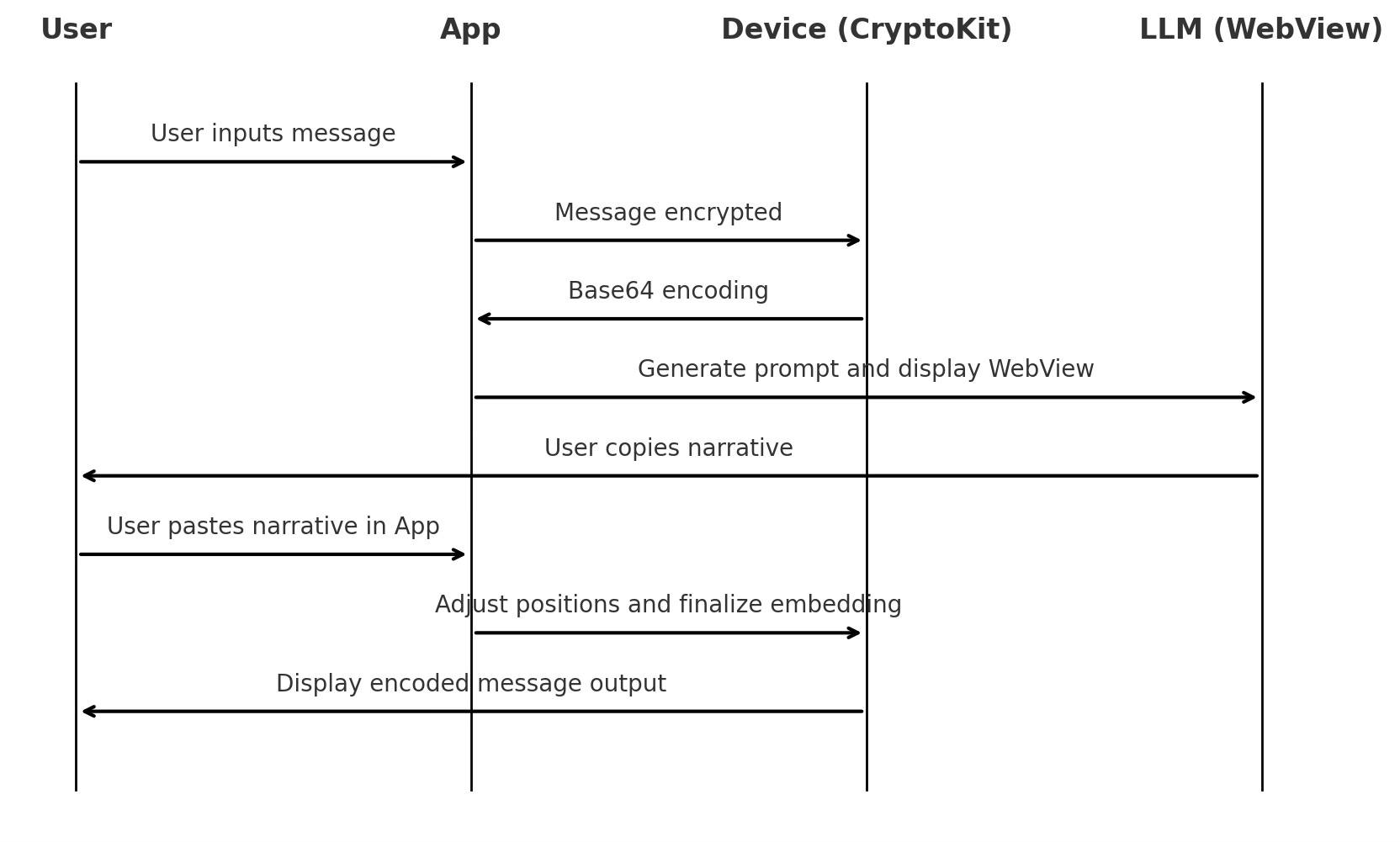
Using numerical position to layer encoded messages.
Hidden Message
Hi pat, great news I'm pregnant, yea I know but John accepted it better than I thought, he's going to have to find a job now I have an appointment at East Main for an utrasound at 6:00 Monday can you drive me
Sub-lex narrative
On a chilly evening, I strolled down East Main, glancing at the quiet houses and nearly empty streets. Just as I passed a small shop, a faint meow reached my ears. I looked around and spotted a tiny, gray kitten huddled near a lamppost. She looked up at me, eyes wide and hopeful, as if she’d been waiting just for me. I couldn’t leave her there, cold and alone. I scooped her up gently, cradling her close to my chest, and decided I’d take her home. My friend Pat was nearby, so I texted, "Hey, can you give us a lift?" Thankfully, Pat agreed, and we headed to the vet to ensure this sweet kitten was okay. She’ll have a fresh start, and maybe a new family—just like me, she’s beginning a journey full of new surprises.
Narrative and Message
Original Message:"I went to my OBGYN today"
Encryption Key:"Itookmydogforalongwalkinthepark!"
Updated Approach Steps
Encrypt the Message:
Use AES-256 encryption with a provided key.
Base64 encode the encrypted result.
Hex Encode the Base64 String:
Convert the Base64 encoded string into a hex string.
Embed Hex String into a Narrative:
Create a narrative that includes all characters from the hex string.
Generate a Results Table:
Map each hex character to its first occurrence in the narrative.
Decoding Process:
Use the results table to reconstruct the hex string.
Convert hex back to Base64, decode, and decrypt the message.
import base64
import hashlib
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad, unpad
# Encrypt the message using AES-256 with Base64 and Hex encoding
def encrypt_message(message, key):
key = hashlib.sha256(key.encode()).digest()
cipher = AES.new(key, AES.MODE_CBC)
ct_bytes = cipher.encrypt(pad(message.encode(), AES.block_size))
iv = base64.b64encode(cipher.iv).decode('utf-8')
ct = base64.b64encode(ct_bytes).decode('utf-8')
encrypted_message = iv + ct
return encrypted_message
# Convert Base64 to Hex
def base64_to_hex(encoded_message):
return base64.b64encode(encoded_message.encode()).hex()
# Create a narrative embedding all hex characters
def create_narrative(hex_string):
narrative_template = [
"In a small town, there lived a cat named Oliver.",
" The cat's best friend was a dog named Buddy.",
" They would often walk together in the park.",
" The park was full of beautiful flowers.",
" One sunny morning, they decided to explore the park.",
" The park had tall trees and winding paths.",
" Oliver loved climbing trees, while Buddy ran around.",
" They met many other animals during their adventures.",
" Buddy enjoyed chasing butterflies in the meadow.",
" Once, they found a hidden pond with clear water.",
" Buddy jumped into the pond with excitement.",
" The pond was surrounded by green grass.",
" Every day, they made new memories.",
" Near the pond, they discovered a secret garden.",
" They dug holes to find hidden treasures.",
" The adventures were always full of surprises.",
" They returned home as the sun set.",
" The park became their favorite place.",
" They lay on the grass, watching the sky."
]
story = "".join(narrative_template)
return story
# Create a results table
def create_results_table(hex_string, story):
return {char: story.index(char) for char in hex_string}
# Decrypt the message
def decrypt_message(encrypted_message, key):
key = hashlib.sha256(key.encode()).digest()
iv = base64.b64decode(encrypted_message[:24])
ct = base64.b64decode(encrypted_message[24:])
cipher = AES.new(key, AES.MODE_CBC, iv)
pt = unpad(cipher.decrypt(ct), AES.block_size)
return pt.decode()
# Example workflow
original_message = "I went to my OBGYN today"
key = "Itookmydogforalongwalkinthepark!"
# Encrypt the message
encrypted_message = encrypt_message(original_message, key)
# Convert to hex
encoded_message_hex = base64_to_hex(encrypted_message)
# Create the narrative
narrative = create_narrative(encoded_message_hex)
print("Narrative:", narrative)
# Generate the results table
results_table = create_results_table(encoded_message_hex, narrative)
print("Results Table:", results_table)
# Decoding
reconstructed_hex_string = ''.join([narrative[i] for i in results_table.values()])
base64_encoded_message = bytes.fromhex(reconstructed_hex_string).decode('utf-8')
decrypted_message = decrypt_message(base64_encoded_message, key)
print("Decrypted Message:", decrypted_message)
Explanation
Hex Encoding:
The Base64 string is converted to hex before embedding into the narrative.
Narrative Construction:
All hex characters (
0-9,a-f) are embedded in a plausible story for obfuscation.
Results Table:
Maps the position of each hex character to its first occurrence in the story.
Decoding:
Hex string is reconstructed, converted to Base64, and decrypted.
Output
Running the script will:
Print the narrative embedding the hex characters.
Show the results table mapping hex characters to positions.
Output the decrypted message: "I went to my OBGYN today".
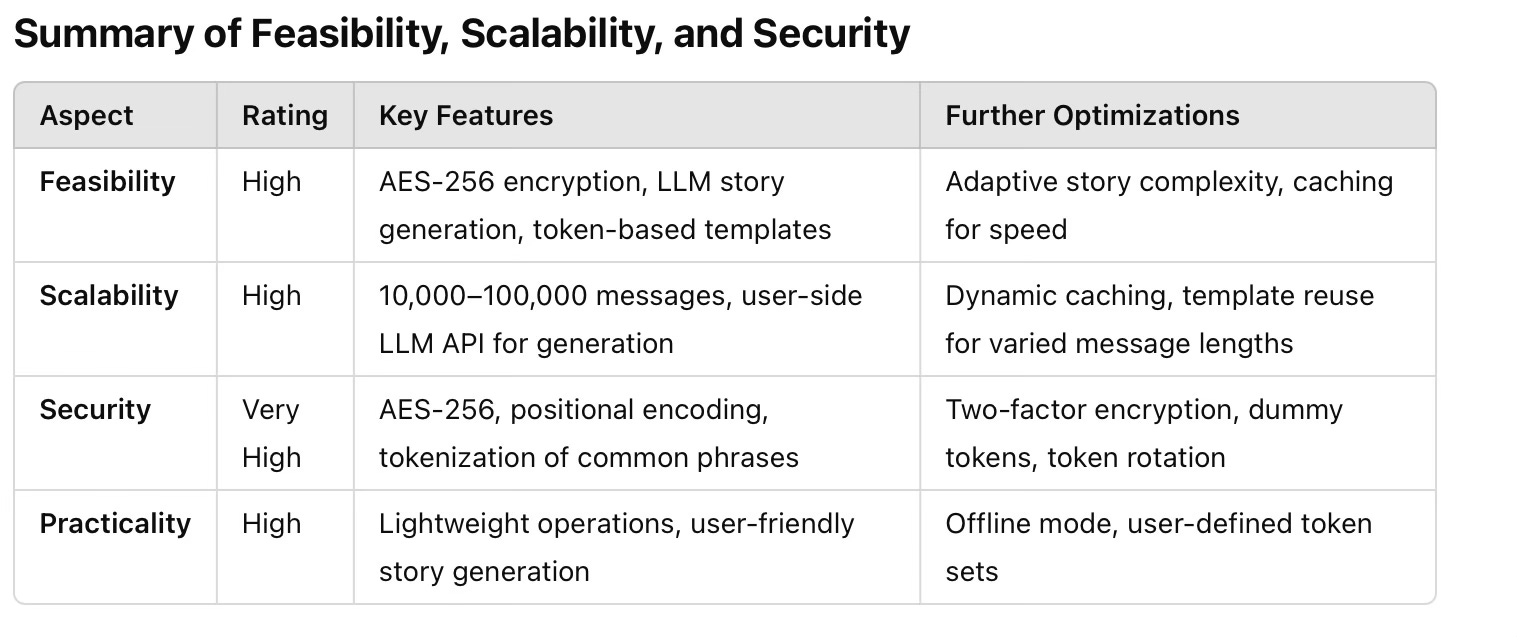
Here is the high-level overview of the project
Project Overview
Goal: Develop a secure communication app that hides encrypted messages within ordinary text narratives.
Core Concept: Use positional encoding and tokens embedded in natural text to conceal messages, leveraging a multi-layered approach to make the hidden data inconspicuous.
Working Names:
Encoding method: "sub-lex" (substitution lexicon).
App: "Private Mirror."
Key Features and Techniques
Security Slider:
Positional Encoding: Highest security but requires a one-to-one text-table update.
Token-Based Encoding: Less secure but easier to use and allows for multi-messaging channels without new table updates.
Embedding Options:
Simple Approach: Start with a random string outside the main post. If it proves insecure, consider more complex embedding methods.
Advanced Options:
Use QR codes for matrix updates, which can be scanned via the app’s camera and appear as random strings.
Explore EXIF metadata or steganography in images, leveraging “dead code” areas or embedded data fields for more covert message storage.
Token Formats for Obfuscation:
Use typo-like patterns, hex-style strings, and symbols to create natural-looking tokens (e.g., “m!ss!ng” instead of “missing”).
Incorporate double characters, mixed case, and subtle special characters for increased realism.
Additional Features and Testing Ideas
Multi-Messaging Concept: Inspired by multispectral analysis in astronomy, with channels like SMS, email, and cloud files each carrying different data layers.
Camera-Based Decoding: Use the device camera to scan printed or QR-encoded data, extracting hidden messages embedded in everyday objects.
Next Steps
Phase 1: Implement the simplest method with a random string for initial testing.
Phase 2: Test with QR codes and explore image-based embedding options if needed.
Long-Term Goals: Complete a scientific paper, develop a high-level overview, build a prototype, run limited beta testing, and use these elements to seek angel funding.
Encoding Rules for Private Mirror Using Sub-Lex
1. Encryption and Base64 Encoding Process
Encrypt the Message: The original message is encrypted using AES-256 (or another secure algorithm), outputting a binary cipher.
Base64 Encoding: Convert the encrypted cipher into a base64 string, creating a limited, predictable character set (A–Z, a–z, 0–9, +, /).
Fixed-Length Blocks: Break the base64 string into consistent blocks (e.g., 4–6 characters each) for easy positioning within the narrative.
2. Positional Matrix Design
Matrix Size: For a 500-character narrative, design a matrix large enough to accommodate each block of the base64 string without altering its position.
Reserved Positions: Identify key positions in the narrative for embedding specific high-value tokens or components of the base64-encoded string.
Redundancy: Allocate a few extra positions in the matrix as backups in case narrative flexibility requires slight shifts. These backup positions won’t affect decoding as long as they’re mapped clearly.
3. Integration of Dummy Tokens
Dummy Token Character: Assign a unique hex code or character (e.g., “FF20”) as a dummy token to represent “neutral” spaces where filler text can be added. This token will prompt the narrative generator to insert unrelated content between segments.
Padding Characters: Base64 strings often end with padding characters (
=). Use these as additional dummy indicators, prompting filler sentences in the narrative to break up and disguise the embedded message.
4. Embedding Process for Base64 Characters
Pre-Canned Placeholder Tokens: Pre-canned tokens (like “I have an appointment at”) will serve as anchor points in the text, with the encrypted message placed between or near these tokens.
Base64 Fragment Placement:
Embed each base64 fragment at a specific position defined by the matrix, surrounding it with context-relevant filler text.
Fragments may be embedded within natural sentence structures (e.g., “in block 4, row 2 of the matrix”) to further obscure the encoded content.
5. Filler Text for Additional Obfuscation
Contextual Sentences: Generate text fragments that naturally surround each segment of the base64 message, keeping the hidden message broken up and distributed within the narrative.
Obscured Address Components: For sensitive elements (like addresses), split characters across multiple segments, each surrounded by filler (e.g., “near 12,” “the big oak,” “at Elm Street”).
6. Decoding Process
Retrieve Base64 Segments by Position: Use the matrix to extract each base64 segment from the predefined positions.
Reconstruct and Decode: Reassemble the base64 string from these positions, decode it, and decrypt the final message.
Example Application of the Rules
Encrypted Message in Base64:
Let’s assume the base64 string is: "MTIzNDU2RWxtRm9y", broken into 4-character blocks.
Narrative with Embedded Base64 Segments:
"Pat, I was at the shelter near T1 an amazing spot by 12. MTIz had a lot of animals needing homes."
"Further down the road, I think around a big oak tree, I saw a sign, NDU2, about Elm."
"Could you pick me up? I should be ready by five or so, maybe at RWxt."
"Bring a few things for our new friend; might be near Rm9y street if you're close by."
Token substitution method, a significant number of stored tokens are designed to appear like mistyped text.
Token Formats with Special Character Substitutions
Common Letter-Like Symbols:
Replace common letters with visually similar symbols, mimicking everyday typing habits.
Examples:
a → @
s → $
i → !
o → 0
l → 1 or |
e → 3
t → +
g → 9
Formats with Special Character Substitutions:
Pattern with Single Substitution: d9@m, 3t5k, h!9J
Double Substitutions: !n9T, r@8$, l1+g
Mixed Substitutions and Numbers: f0r3, k+7!, @5x!
Longer, Complex Tokens with Multiple Substitutions:
Add multiple substitutions to create complex-looking tokens, making them even less recognizable.
Examples: @r+1m5, h3$+4k, m!9@5L, c0n+3$
Examples in Context:
“I have an appointment at” might look like 3pp0intm3nt@ or @ppt+mnt3
“Can you meet me around” could appear as c@n y0u m33+
“Will you pick me up at” might be wi11 y0u p1ck or p!cK m3 u+
Sample Tokens Using Special Character Substitutions
Using this approach, here’s a list of sample tokens that appear as typos or substitutions, blending seamlessly into text:
h3@rt
m1ss!ng
+3st
4pp!3
w0nd3r
b@ck+0p
9r@nd3
+yp3
@dm1n
c0d3r
Advantages of Using Character Substitutions
Natural Appearance: These tokens appear even more realistic, mimicking natural typos or intentional substitutions people use daily.
Increased Obfuscation: Replacing letters with similar-looking symbols makes the tokens look like they’re part of normal communication, blending into any text environment.
Flexibility Across Contexts: Whether it’s a sentence, a label, or a note, these tokens will feel like common shorthand or typos, making detection difficult.
Phase I ProtoType